Overview
之前项目的人遗留的数据被接管后进行了改造,现在处理数据都用Spark来做了。这里记录一下如何在Mac本地的IntelliJ IDEA中搭建一个简单的Spark项目。这里不涉及HDFS这些相关的内容,只记录Spark。
在此之前,我们默认已经安装好了最新版的IntelliJ IDEA以及配置好了JDK。
1. IDEA中安装Scala插件
在IDEA的启动页面,点击Configure,在下拉列表中选择Plugins。
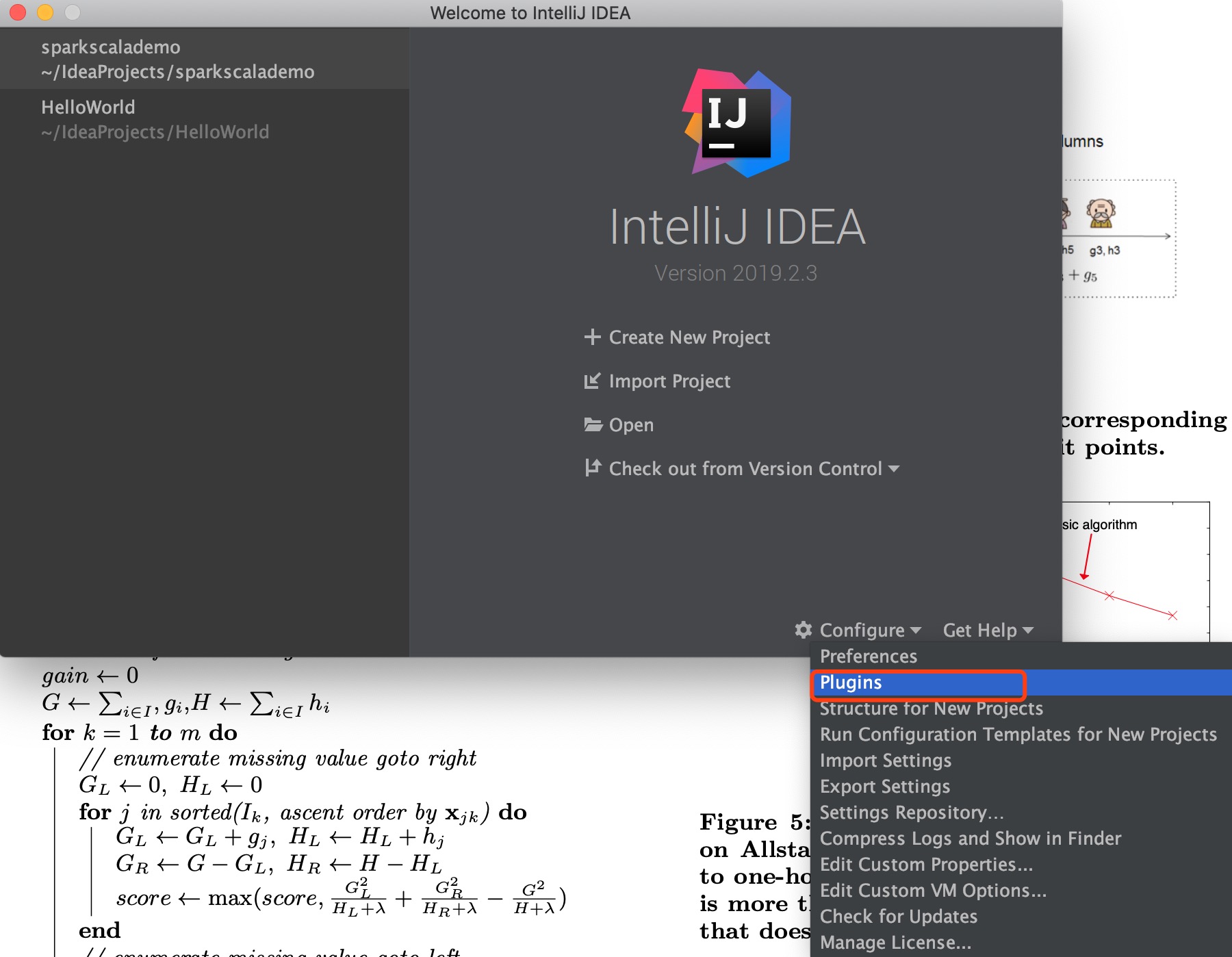
在左边输入框内搜索Scala,点击安装即可。这样我们就安装好了Scala。
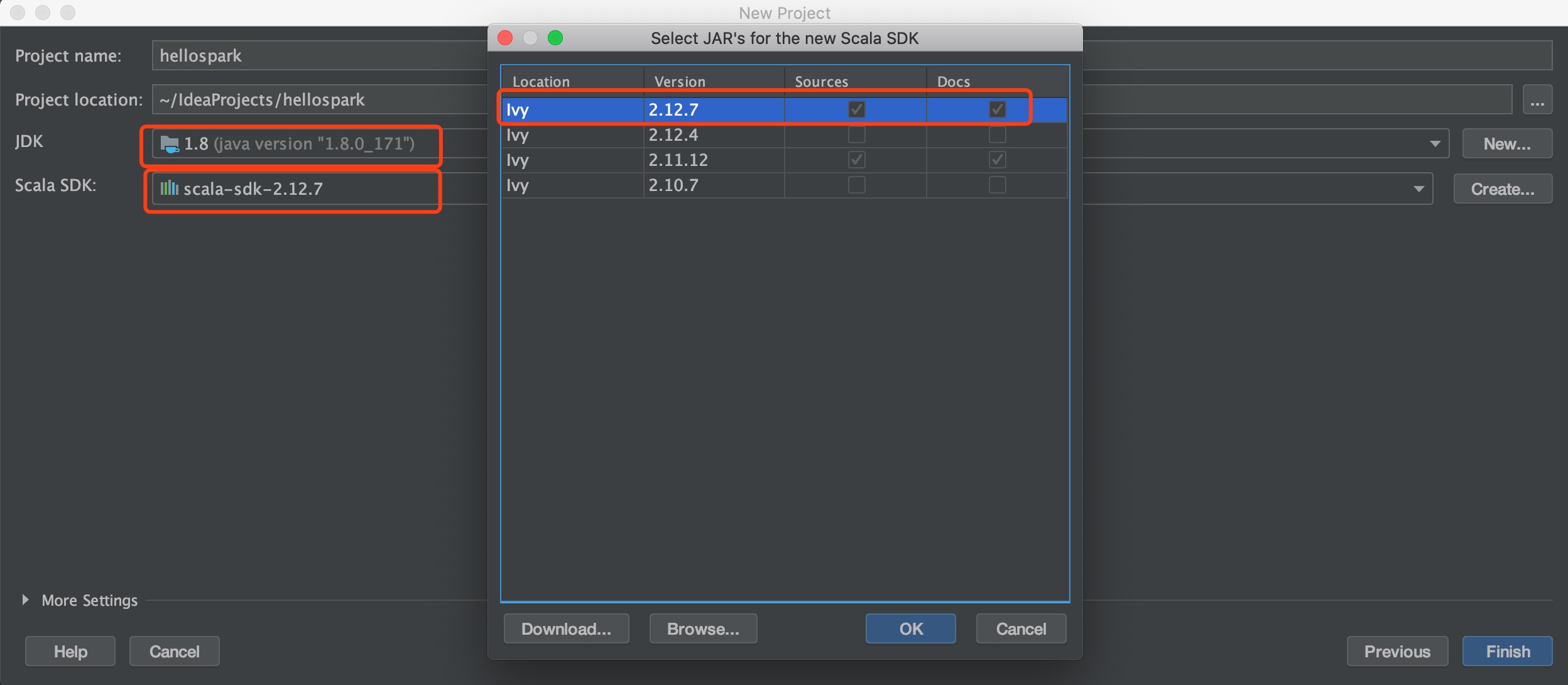
接着回到刚刚的启动页面,选择Create New Project,选择Scala,右边的4个选项需要选IDEA,点击Next,项目名字我们就叫做hellospark吧,选好JDK后,选择Scala SDK,点击Create,我喜欢新的,所以选择了最新版本的scala-sdk-2.12.7(这一步导致了后面的异常),点击Finish。
2. 安装Spark2.4.4
登录到Spark官网,下载最新的稳定版本Spark2.4.4的压缩包。
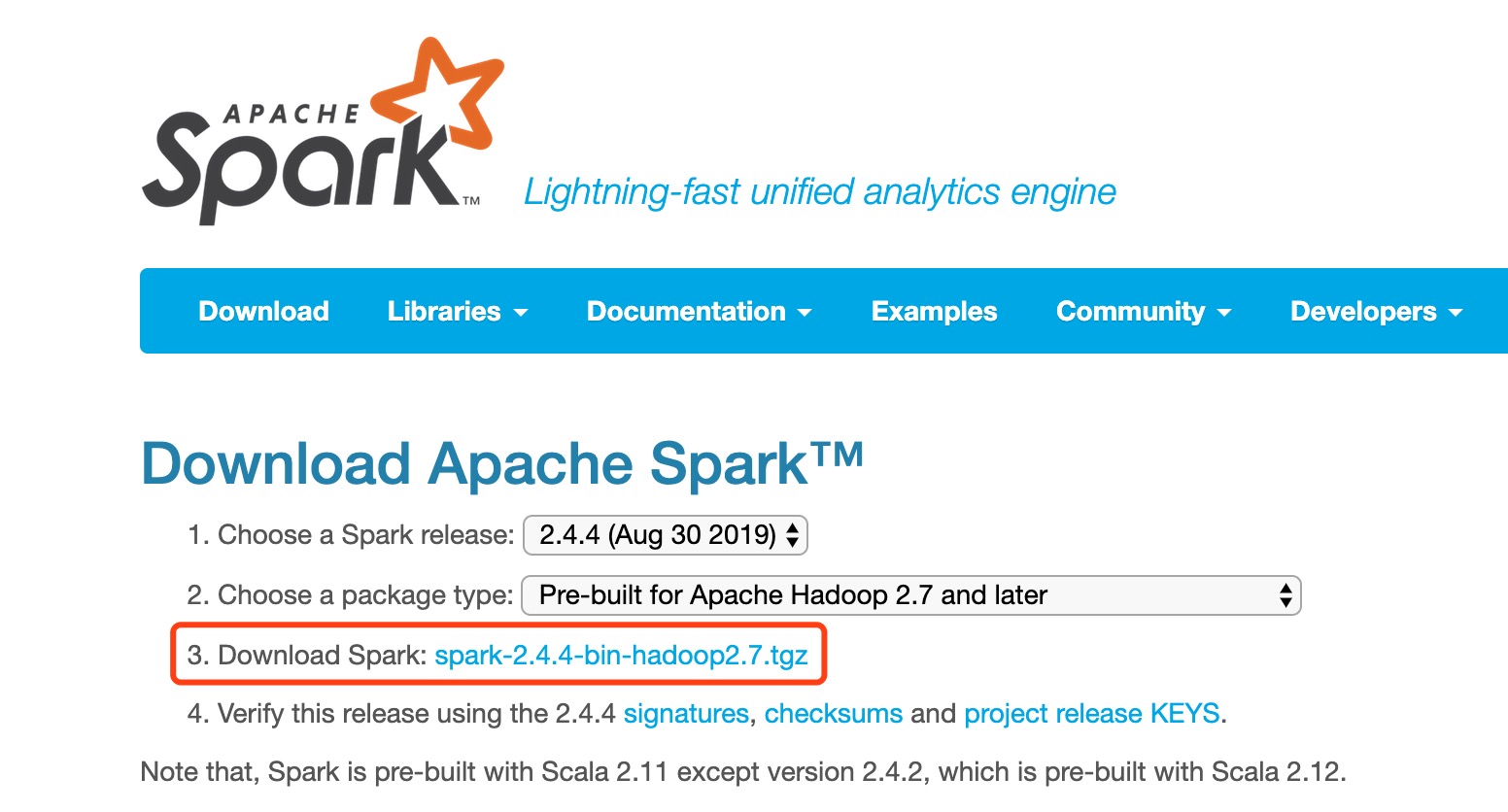
在本地解压缩下载的压缩包,记住解压地址。
点击File -> Project Structure,弹出的窗口点击Libraries,点击Java,
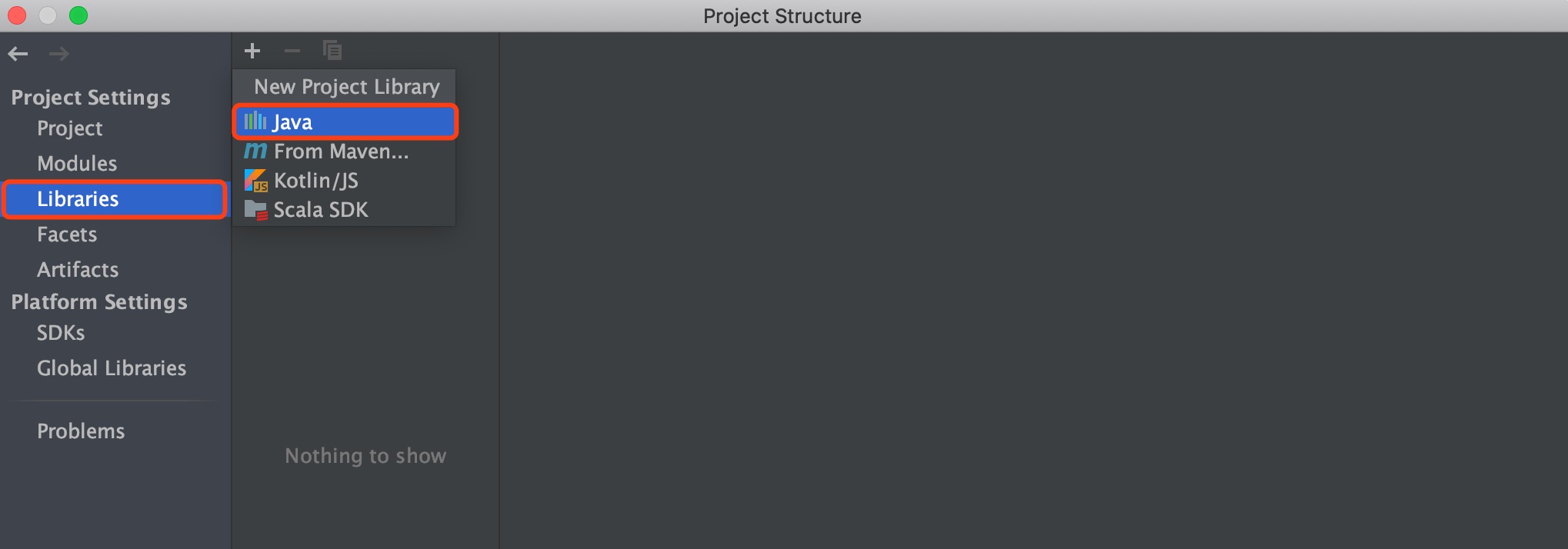
然后选择从解压的Spark压缩包里面找jars文件夹,
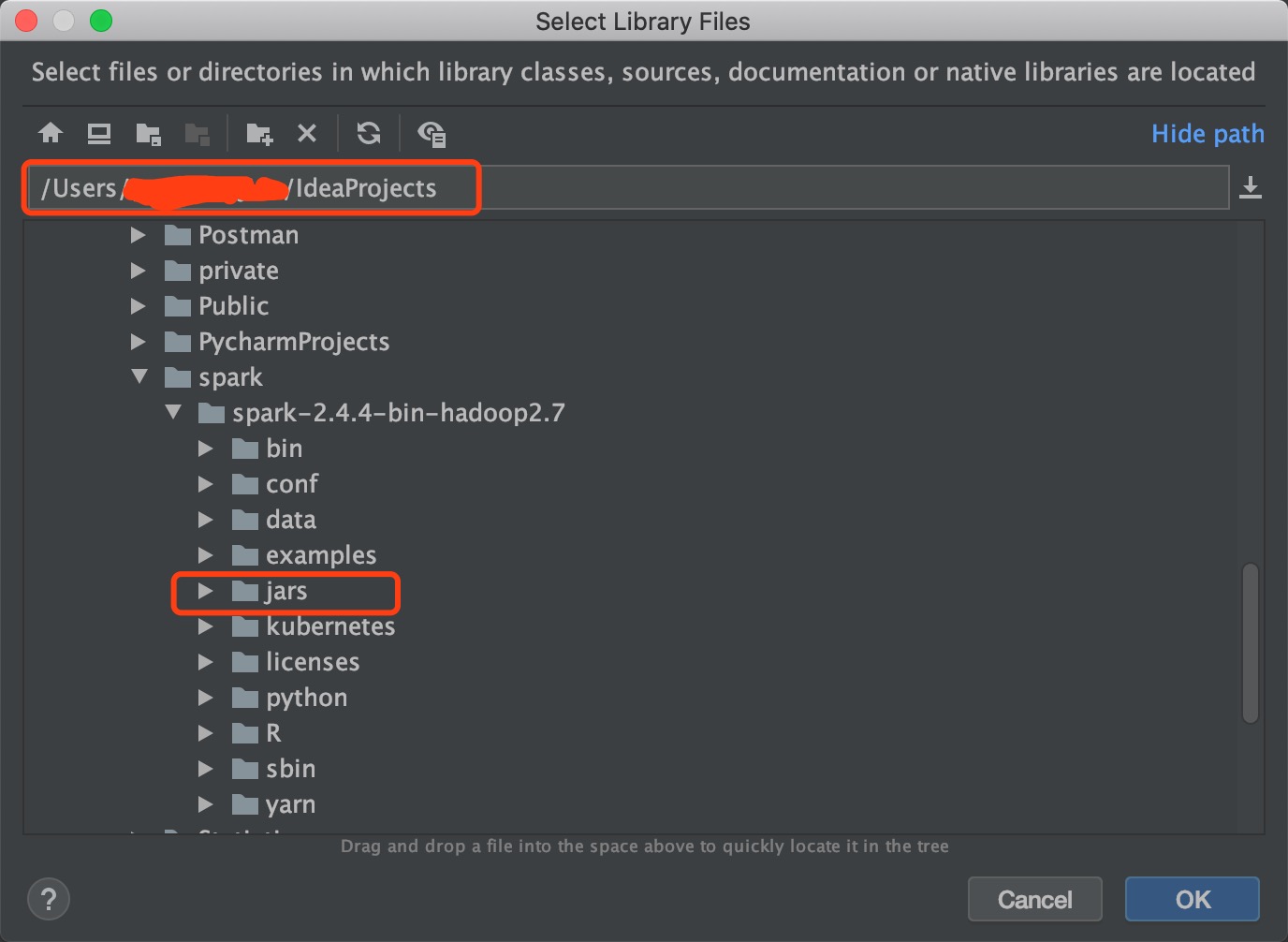
点击OK之后,会弹出来让选择模块的对话框,选择hellospark即可。
3. 编写Scala程序
下面来试试是不是我们的环境是不是可行。
在src文件夹上右击,新建一个Scala Class,选择Object,名字叫HelloWorld。HelloWorld.scala内容如下:
import org.apache.spark.{SparkConf, SparkContext}
object HelloWorld {
def main(args: Array[String]): Unit={
val conf = new SparkConf()
.setAppName("first spark")
.setMaster("local[1]");
new SparkContext(conf)
.parallelize(List(1,2,3,4,5,6,7,8,9,10)) //传入可迭代对象
.map(x => x*x) // 平方运算
.filter(_%9 == 0) //只要可以被9整除的
.collect()
.foreach(println);
}
}
在文件内右击选择Run 'HelloWorld',抛出如下异常:
Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
at org.apache.spark.util.Utils$.stringToSeq(Utils.scala:2664)
at org.apache.spark.internal.config.ConfigHelpers$.stringToSeq(ConfigBuilder.scala:49)
at org.apache.spark.internal.config.TypedConfigBuilder$$anonfun$toSequence$1.apply(ConfigBuilder.scala:125)
at org.apache.spark.internal.config.TypedConfigBuilder$$anonfun$toSequence$1.apply(ConfigBuilder.scala:125)
at org.apache.spark.internal.config.TypedConfigBuilder.createWithDefault(ConfigBuilder.scala:143)
at org.apache.spark.internal.config.package$.<init>(package.scala:172)
at org.apache.spark.internal.config.package$.<clinit>(package.scala)
at org.apache.spark.SparkConf$.<init>(SparkConf.scala:716)
at org.apache.spark.SparkConf$.<clinit>(SparkConf.scala)
at org.apache.spark.SparkConf.set(SparkConf.scala:95)
at org.apache.spark.SparkConf.set(SparkConf.scala:84)
at org.apache.spark.SparkConf.setAppName(SparkConf.scala:121)
at HelloWorld$.main(HelloWorld.scala:5)
at HelloWorld.main(HelloWorld.scala)
是Scala SDK版本太新了,我们需要更换版本。
点击File -> Project Structure,弹出的窗口点击Global Libraries,点击Scala SDK,点击-号,把2.12.7版本删掉;接着点击+号,点击点击Scala SDK,选择2.11.12版本。配置好以后,右击hellospark项目,选择Rebuild Module 'hellospark'。再运行程序,程序就正确产生结果9,36,81了。
4. 设置log输出级别
在使用Spark的时候,控制台会默认把所有的日志信息全部输出,那我们调试的时候会非常麻烦,我们可以把INFO级别的日志给过滤掉。只需要很少的代码。
首先引入Level和Logger:
import org.apache.log4j.{Level, Logger}
然后在main函数当中添加下面一句:
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
再运行,就不会显示INFO级别的日志了。
本文主要参考了以下文章:
idea设置控制台不打印日志